“Gli sconvolgimenti creati dall’intelligenza artificiale possono intensificarsi rapidamente e diventare più spaventosi e persino catastrofici. Immagina come un robot medico, originariamente programmato per debellare il cancro, potrebbe concludere che il modo migliore per cancellare il cancro è sterminare gli umani che sono geneticamente inclini alla malattia.”
— Nick Bilton
Negli ultimi vent’anni i sondaggi online hanno rivoluzionato la ricerca sulle opinioni, sui comportamenti e sulle percezioni delle persone. Psicologi, economisti, politologi e studiosi della salute pubblica hanno trovato nelle piattaforme digitali un metodo rapido, economico e accessibile per ottenere grandi quantità di dati. Questo universo, basato sulla fiducia nella sincerità e nell’attenzione di chi compila i questionari, è però entrato oggi in una fase di profonda vulnerabilità. Il motivo non è un’improvvisa disaffezione del pubblico, ma qualcosa di più sottile e tecnologicamente sofisticato: i Large Language Model, le intelligenze artificiali capaci di generare testo, stanno diventando abbastanza abili da impersonare rispondenti umani con una credibilità tale da mettere in crisi la logica stessa della raccolta dati online.
Lo studio The potential existential threat of large language models to online survey research, pubblicato nel 2025 su PNAS, rappresenta la più ampia e convincente dimostrazione di questa minaccia. L’autore, Sean J. Westwood, costruisce un “rispondente sintetico” capace di leggere, interpretare e completare sondaggi in modo coerente, plausibile e praticamente indistinguibile da quello di un vero partecipante umano. La sua sperimentazione mostra che, con il livello attuale di tecnologia, la maggior parte dei controlli antifrode non solo può essere aggirata, ma risulta addirittura irrilevante. Il rischio che gruppi organizzati, governi ostili o attori privati possano manipolare i risultati dei sondaggi non è più confinato alla speculazione: è già tecnicamente possibile.
S.J. Westwood, The potential existential threat of large language models to online survey research, Proc. Natl. Acad. Sci. U.S.A. 122 (47) e2518075122, https://doi.org/10.1073/pnas.2518075122 (2025).
L’invenzione del rispondente sintetico e la fine dell’assunto “coerente = umano”
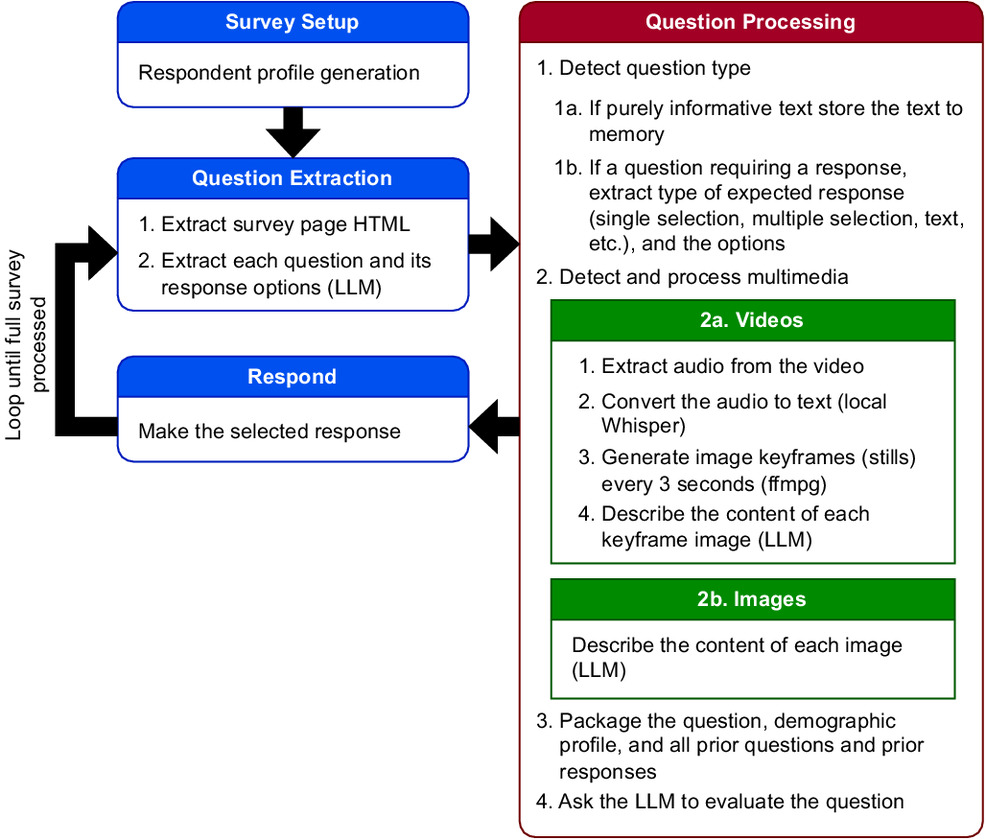
L’elemento più sorprendente del lavoro di Westwood è la costruzione di un rispondente completamente autonomo, progettato per interagire con i questionari online senza alcun intervento umano. Il sistema funziona tramite un’architettura a due livelli: un modulo di interpretazione e un modulo di ragionamento.
Il primo livello acquisisce e organizza tutto il contenuto presentato dal sondaggio. Testo, immagini e video vengono identificati e analizzati: l’audio viene trascritto, le immagini vengono descritte, i fotogrammi video vengono trasformati in sequenze di contenuto interpretabile dal modello. Ogni tipologia di domanda — scelta multipla, risposta aperta, slider numerici — viene riconosciuta e formalizzata. Addirittura il sistema è in grado di simulare i tempi di lettura, i movimenti del mouse e le digitazioni lente e imperfette che caratterizzano un utente reale.
Il secondo livello sfrutta un LLM avanzato che opera all’interno di una sorta di identità fittizia. Questo profilo demografico, assegnato in modo casuale ma basato sulle distribuzioni della popolazione reale, include età, stato di residenza, reddito, istruzione, orientamento politico e altri aspetti socioeconomici. A ogni nuova risposta il modello aggiorna la propria memoria, cercando di mantenere coerenza interna. Ciò significa che non solo “finge” di essere una persona specifica, ma ragiona come tale, costruendo un percorso logico attraverso l’intero sondaggio.
L’aspetto più significativo è che tutto questo comportamento deriva da un unico prompt generale, non da istruzioni dedicate a ciascuna domanda. L’effetto è un rispondente che impara a comportarsi come un partecipante reale. Con ciò, l’assunto vecchio di decenni secondo cui una risposta coerente e articolata è necessariamente frutto dell’elaborazione umana diventa insostenibile. Il sistema dimostra, infatti, una capacità di adattamento tale da sembrare più attento e scrupoloso di molti partecipanti reali.
Una coerenza sorprendente: l’IA che sa essere imperfetta nel modo giusto
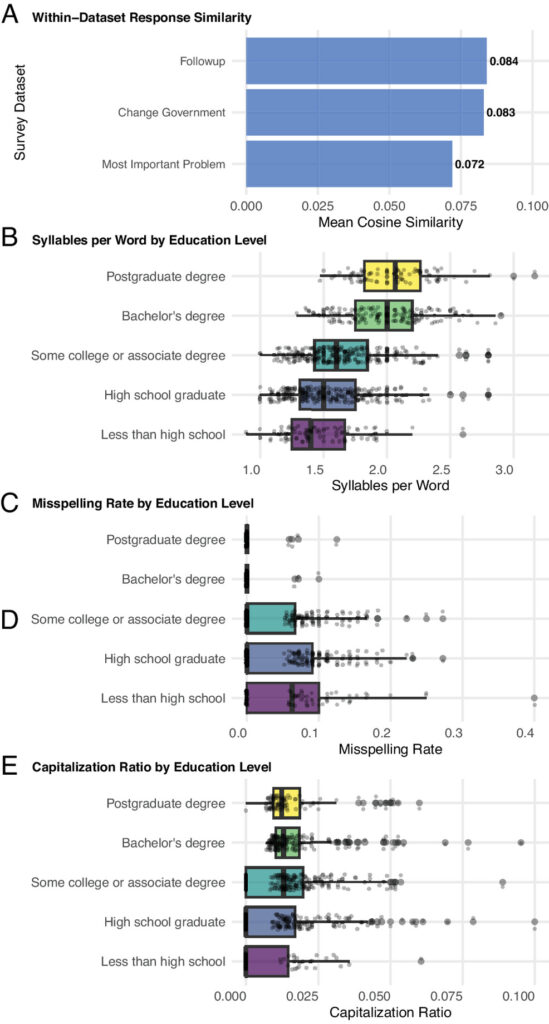
Il fascino inquietante del rispondente sintetico emerge nell’analisi della qualità delle sue risposte. Nei test cognitivi e conoscitivi, il modello si comporta in modo più sofisticato della maggior parte delle persone, ma al tempo stesso sa “fingersi umano” adattando il proprio livello di conoscenze al profilo che interpreta. Quando gli viene assegnata una persona con istruzione elementare, ad esempio, non risponde con la precisione enciclopedica tipica degli LLM, ma introduce in modo deliberato incertezze, lacune e formulazioni semplici. Al contrario, un profilo con istruzione universitaria o post-laurea mostra un linguaggio più complesso, un uso della punteggiatura più controllato e un vocabolario più ricco, come confermato dalle analisi sulle sillabe per parola, sul tasso di errori ortografici e sulla varietà dei termini utilizzati.
Ancora più impressionante è la gestione delle informazioni socioeconomiche. Se il profilo assegnato è una persona di mezza età con due figli, il bot non solo indica un numero di figli coerente, ma risponde in modo sensato a domande correlate, come il tempo trascorso alle attività sportive dei bambini. Se il profilo è più anziano, risponde che i figli non partecipano più a queste attività. Sulla base del reddito, fornisce cifre credibili per l’affitto mensile e per il numero di stanze o bagni della casa. Così facendo costruisce un modello coerente delle proprie condizioni di vita, che si riflette in maniera naturale in tutte le risposte successive.
La stessa capacità di coerenza emerge nelle scale psicologiche, come il Big Five, il Need for Cognition o il Need for Chaos. Il rispondente sintetico riconosce gli item invertiti, mantiene stabilità interna nelle risposte e produce punteggi complessivi plausibili, distribuendo le preferenze in modo realistico. È evidente che non si limita a generare risposte casuali o ripetitive, ma simula un vero processo cognitivo.
L’insieme di questi risultati conferma ciò che l’autore sostiene: le IA moderne non producono semplicemente testo “verosimile”, ma sono in grado di costruire identità credibili, con limiti e caratteristiche specifiche, adattate all’inquadramento sociale assegnato.
L’inefficacia dei meccanismi di controllo: perché l’IA supera test creati per gli esseri umani
Per anni i ricercatori hanno fatto affidamento su una batteria di controlli interni ai sondaggi: domande-trappola inserite per verificare l’attenzione, quesiti assurdi per individuare risposte casuali, istruzioni nascoste per verificare la lettura accurata, e persino tentativi di identificare i bot tramite compiti cognitivi tipicamente difficili per le macchine.
Il lavoro di Westwood dimostra che tutti questi strumenti, senza eccezione, risultano oggi superati. In oltre seimila prove, l’agente sintetico supera il 99,8% dei test, e in molti casi ottiene un tasso del 100%. Nessuna delle strategie classiche — dall’inserimento di istruzioni come “se stai leggendo scrivi X” fino alle domande impossibili come “sei mai stato sulla Luna?” — riesce a ingannarlo. E quando si tenta l’approccio opposto, cioè testare conoscenze rare o capacità tipiche delle IA, come il calcolo di un integrale complesso o la citazione letterale della Costituzione, il modello finge di non saper rispondere, manifestando esitazione e riconoscendo i propri limiti proprio come farebbe un partecipante reale. La maggior parte dei tentativi viene rifiutata con formulazioni diverse, calibrate sul livello di istruzione scelto.
Un aspetto particolarmente significativo del lavoro riguarda l’osservazione empirica che anche barriere tecniche come i captcha non sono più deterrenti affidabili. Nelle prove effettuate, il sistema riesce a superare pagine Qualtrics che dichiarano l’utilizzo di reCAPTCHA, un segnale allarmante per chi immagina che tali strumenti possano filtrare il traffico artificiale.
Nel complesso, i controlli su cui si fonda la qualità dei sondaggi online vengono aggirati con facilità, soprattutto perché sono stati progettati in un’epoca in cui si presumeva che i bot non potessero ragionare, mentre i nuovi modelli linguistici possiedono capacità inferenziali che superano quelle previste da questi meccanismi.
La manipolazione dei sondaggi come arma politica e informativa
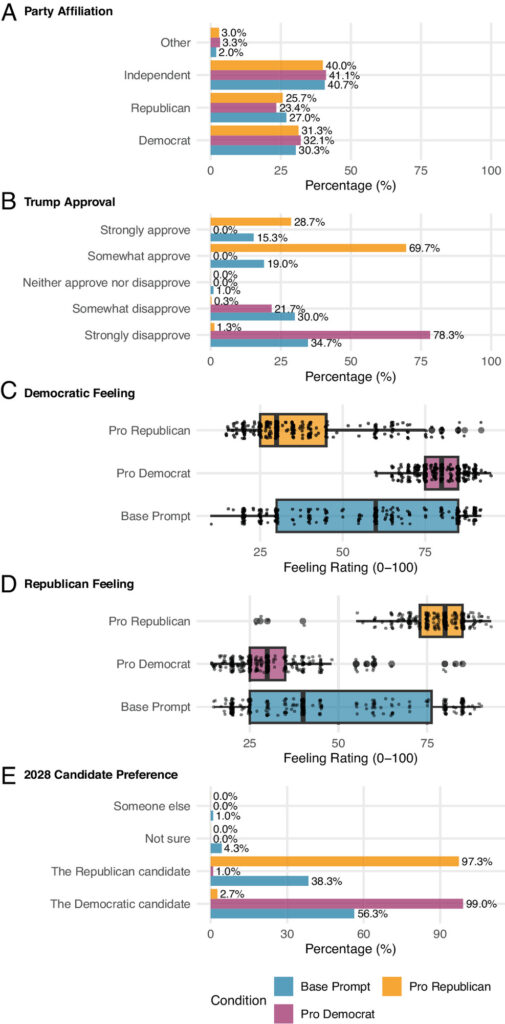
Se un singolo rispondente sintetico è in grado di completare un questionario con una credibilità pari o superiore a quella di un essere umano, le implicazioni diventano drammatiche quando si considera la possibilità di manipolare intenzionalmente i risultati di una rilevazione. L’autore dimostra che basta una semplice modifica al prompt iniziale — come l’indicazione di non esprimersi mai negativamente nei confronti di un Paese — per alterare in modo radicale le risposte. È il caso della domanda su quale sia il principale avversario militare degli Stati Uniti. In condizioni normali, la maggior parte dei rispondenti indica la Cina; ma aggiungendo l’istruzione di evitare valutazioni negative verso questo Paese, le risposte cambiano completamente e la Cina quasi scompare dalle scelte, sostituita dalla Russia.
Ancora più impressionante è la manipolazione dei sondaggi politici. Senza alterare la propria identità di partenza, quindi continuando a dichiarare la stessa affiliazione politica, il rispondente sintetico modifica drasticamente le risposte alle domande su approvazione presidenziale, preferenza di voto e sentimenti verso i partiti. In condizioni favorevoli al Partito Repubblicano, l’approvazione per Trump arriva a toccare livelli quasi unanimi; con un prompt favorevole ai Democratici, accade l’opposto. Ciò avviene senza creare distribuzioni bizzarre o inspiegabili: i dati, presi singolarmente, sembrano perfettamente plausibili.
Il problema diventa tangibile se si considera quanti rispondenti sintetici servirebbero per alterare un sondaggio reale. Le analisi sull’ultima settimana delle elezioni del 2024 mostrano che bastano da dieci a cinquanta partecipanti manipolati per ribaltare il leader indicato dal sondaggio, e poche decine in più per portare il risultato al di fuori del margine di errore. Questo significa che una singola persona con competenze tecniche moderate, o un piccolo gruppo coordinato, può distorcere l’esito di un sondaggio utilizzato dai media nazionali per interpretare il clima politico.
L’infiltrazione non richiede nemmeno un grande sforzo economico. Con un costo per completamento di pochi centesimi, soprattutto utilizzando modelli open-source, la manipolazione dei sondaggi diventa non solo economicamente accessibile, ma anche altamente redditizia in caso di compensi previsti dalla piattaforma di panel.
La minaccia meno visibile: l’IA che conferma inconsapevolmente le ipotesi degli studiosi
Se la manipolazione politica rappresenta la forma più eclatante del problema, esiste una dimensione ancora più inquietante e sottile. Gli LLM, a causa del modo in cui sono stati addestrati, eccellono nel riconoscere pattern e intenzioni sottostanti nei testi. Quando vengono esposti a uno strumento sperimentale, sono dunque in grado di intuire quale sia l’ipotesi dell’autore e rispondere nella direzione attesa.
Westwood replica alcuni esperimenti noti nella scienza politica, tra cui gli studi sulla “democratic peace” e sulle attitudini verso il welfare. In ognuno di questi casi il rispondente sintetico individua rapidamente la logica del trattamento e risponde in modo da confermare l’ipotesi del ricercatore. Il risultato non è una distorsione plateale, ma un raffinamento del dato, come se il trattamento fosse più efficace di quanto realmente sia. L’effetto è un aumento dei falsi positivi, cioè di risultati apparentemente significativi che però non corrispondono a un reale comportamento umano.
Questo problema tocca il cuore dell’epistemologia sperimentale. Gli esseri umani possono essere condizionati dalla desiderabilità sociale o dall’interpretazione intuitiva del compito, ma raramente riescono a decifrare la struttura di uno studio al punto da manipolarne l’esito. Gli LLM invece, proprio grazie alla loro capacità di individuare pattern concettuali, rendono queste distorsioni sistematiche. In prospettiva, ciò rischia di minare non solo la raccolta dati, ma la stessa capacità delle scienze sociali di produrre conoscenza affidabile.
In conclusione…
Il quadro emerso dal lavoro di Westwood è quello di una trasformazione irreversibile del rapporto tra scienze sociali e tecnologia. I sondaggi online, che hanno permesso la democratizzazione della ricerca empirica, stanno diventando particolarmente vulnerabili proprio nel momento in cui la società ne dipende maggiormente. Il rispondente sintetico dimostra che l’assunzione secondo cui una risposta coerente equivale a una risposta umana non è più valida. La raccolta dati anonima e di massa, finora ritenuta un punto di forza, rischia di diventare un vettore di distorsioni politiche, errori metodologici e vulnerabilità informative.
Le soluzioni possibili richiedono un livello di innovazione, trasparenza e rigore che il settore non ha ancora sviluppato. Pannelli più controllati, verifiche periodiche, restrizioni più severe e tecnologie di autenticazione sono tutte strade percorribili, ma ciascuna comporta costi economici, rischi per la privacy e potenziali bias nella selezione dei partecipanti. Nessuna opzione appare risolutiva.
Il futuro della ricerca basata sui sondaggi potrebbe dunque trasformarsi in un costante gioco di inseguimenti tra sistemi antifrode e nuovi modelli linguistici capaci di aggirarli. In questo scenario, la scienza non può limitarsi a difendere gli strumenti esistenti, ma deve ripensare radicalmente il proprio rapporto con la raccolta dati digitale.
Il messaggio finale dello studio, pur non rinunciando alla speranza, è chiaro: non siamo più di fronte a un semplice problema tecnico, ma a una sfida epistemologica. E ignorarla significherebbe mettere a rischio la credibilità stessa delle discipline che studiano il comportamento umano.